“But it must be recognised that the notion of ‘probability of a sentence’ is an entirely useless one, under any known interpretation of this term.”
Chomsky (1969)
Are language models a waste of time?
I recently found this post in my drafts, having written it over the Christmas period in 2017. Having talked with several technologists about so-called “AI”, I’ve realised that there is a wide public misconception about language models and how they are used. In this post I try to explain to myself, and anyone who feels like reading it, the properties of language models and their limits.
What is a language model?
A language model can be defined as a system that computes probabilities for sequences of tokens:

where the output is a probability value between 0 and 1 and t is a vector containing a sequence of tokens, 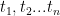
Languages have multiple levels of abstraction. The tokens can thus be:
- characters (e.g. ‘a’, ‘.’, ‘ ‘);
- words (e.g. ‘cat’, ‘mat’, ‘the’); or
- larger word groups such as sentences or clauses.
So in one sense, a language model is a model of the probability of a sequence of things. For example, if you are given a particular set of words “the cat sat on the mat“, the language model can provide a probability value between 0 and 1 representing the likelihood of those tokens in the language.
Conditional Models
Another form of language model is a conditional token model. This looks to predict tokens one at a time given a set of previous tokens.

Here we have a function that provides a probability value for a particular token at position 


Normally, we have a set of possible token values. For example, we might have a dictionary of words, where a token 
If you hear phrases such as “local effects” and “long range dependencies”, these relate to the number of tokens we need to add into the language model to predict the next token. For example, do we need all the previous tokens in a document or just the last few?
Language as Numbers
Now computers only understand numbers. So,
“hello”: 456 – the 456th entry in an array of 10,000 words.
…
“world”: 5633 – the 5633th entry in an array of 10,000 words.
…
So “hello world” = [456, 5633].
Building Language Models
Language models are typically constructed by processing large bodies of text. This may be a set of documents, articles in Wikipedia, or all webpages on the Internet. Hence, the output probability can be seen as a likelihood for a sequence of tokens, or a next token, based on some form of historical data.
For example, over a corpus of English text, “the cat is black” would have a higher probability value (e.g. 0.85) than “dog a pylon” (e.g. 0.05). This form of model is actually present in most pockets – it is difficult to type the last example on a smartphone, as each word is autocorrected based on a likely word given the characters.
A simple language model can be built using n-grams. N-grams are sequences of tokens of length n. Before the most recent comeback of neural network models, state of the art transcription and translation systems were based on n-grams. You can generate an n-gram model by simply counting sequences of tokens. For example, “the cat is black” contains 3 bi-grams (n=2) – “the cat”, “cat is”, “is black”. Over a large enough corpus of text “the cat” will occur more times than “cat the” and so “the cat” can be assigned a higher probability value proportional to its frequency.
The latest state of the art language models use recurrent neural networks. These networks are parameterised by a set of weights and biases and are trained on a corpus of data. Using stochastic gradient descent and back propagation on an unrolled network, values for the parameters can be estimated. The result is similar to the n-gram probabilities, where the frequency of relationships between sequences of characters influence the parameter values.
What Language Models Are Not
Over the last 10 or 20 years there have been great strides in analysing large bodies of text data to generate accurate language models. Projects such as Google books and the Common Crawl have built language models that cover a large proportion of the written word generated by human beings. This means we can now fairly accurately provide bounds of how likely a sequence of tokens is.
However, issues often when people naively try to use language models to generate text. It is often the case that the most likely sentence, given a corpus, is not the sentence we want or need. Indeed, for a sentence to have high (human) value it often needs to express something new, and so it will diverge from the corpus of past sentences. Hence, a “good” sentence (from a human task perspective) may have a lower probability in our language model than a “common” sentence.
As an exercise for you at home, try to dictate an unusual sentence into your phone. The likely outcome is that the phone tries to generate the most likely sentence based on history rather than the sentence you want to generate.
You also see this with toy implementations of recurrent neural networks such as CharRNN and its varieties. These networks seek to estimate a probability distribution over a vocabulary of terms; what is being generated is likely sequences of tokens given the training data. These toy implementations are what the popular press pick up on as “AI” writers. However, they are nothing more than sequences of likely tokens given a dataset.
Often the toy implementations appear to be smart because of the stochastic nature of the probabilistic models – each sequence will be slightly different due to probabilistic sampling of the token probabilities (plus things like searches over the probabilities). Hence, you will get a slightly different output every time, which looks more natural than a single most likely sentence. However, a closer reading shows that the outputs of these systems is gibberish.
So language models are not generative models, at least not in their popular form.
How Do You Generate Text?
Another exercise: tell me a sentence. Any sentence whatsoever.
It’s harder than it looks. People will generally do one of several things:
- pick archetypal sentences “the quick brown fox…” “the X did Y”, where most of these are conditionally learnt at a young age;
- pick a sentence based on what they were doing immediately prior to the question; or
- look around and pick something in their field of view. The experiment is even more fun with children, as the thought processes are often more transparent.
This test demonstrates a simple truth: the concept of a “random” sentence rarely occurs in practice. All language is conditional. It is easier to provide a sentence about something.
Here are some things (amongst a near infinite multitude of things) that influence what words we select:
- Document type (report, blog post, novel);
- Audience (children, adults, English professors);
- Location in document (start, middle, end);
- Characters and character history;
- Country;
- Previous sentences/paragraphs/chapters; and
- Domain (engineering, drama, medical).
The better we get at modelling what we are talking about, the better our generative language models.
This is partially seen with summarisation systems. Some of these produce pretty coherent text. The reason? The context is severely constrained by the content of the piece of writing we are summarising.
Distributed Sensory Representations
There is more. Vision, sound and motor control can teach us a lot about language. Indeed different facets of language have piggybacked on the underlying neural configurations used for these abilities. All these areas have distributed hierarchical representations. Complex features are represented by fuzzy combinations of lower features, and at the bottom you have raw sensory input. There is no neuron for “banana” but a whole series of activations (and activation priming) for different aspects of a “banana”. Visualisations of feature layers in convolutional neural network architectures show how complex object representations may be constructed from a series of simple features, such as edges. It is likely that a semantic representation of a word in our brains is similarly constructed from webs of component representations over several layers.
Yet another question: how does a person blind from birth imagine an orange?
I don’t know the answer to this. (I need to find some research on it.) I’d hazard to guess that the mental representation is built from many non-visual sensory representations, where these may be more detailed than an average sighted person. But the key is they still “know” what an orange is. Hence our semantic representations are distributed over different sensory modalities as well as over different layers of complexity.
So I believe we are getting closer to useful generative language models when we look an systems that produce simple image caption labels. These systems typically use a dense vector representation of an image that is output by a convolutional neural network architecture to condition a recurrent neural network language model. The whole system is then trained together. Here the dense vector provides an “about” representation that allows the language model to pick the most likely words, given the image. The surreal errors these systems make (a baseball bat is a “toothbrush”) show the limitations of the abstract representations conditioning the text generation.
Another issue that tends to get ignored by academic papers I have seen is the limitation of selecting a particular input representation. Many systems start with clean, easily tokenised text sources. The limited time scales of research projects means that words are often picked as the input layer. Hence, the language model looks at providing word probabilities over a vocabulary. Often word embeddings are used on this input, which introduces some aspects of correlation in use. However, in our brains, words seem to be an intermediate representation; they are features built upon sounds, phonemes and lower symbols (e.g. probably at least several layers of representations). Given that language is primarily oral (writings is a relatively new bolt on), I’d hazard that these lower levels influence word choice and probability. (For example, why do you remember “the cat on the mat” more than “the cat on the carpet”?) Word embeddings help to free us from the discrete constraints of words as symbols but they may be applying use patterns too early in the layers of representations.
Looking at how motor activity is controlled in the brain, we find that our cortex does not store detailed low-level muscle activation patterns. Through training these patterns are often pushed out of the cortex itself, e.g. into the cerebellum, spinal cord or peripheral nervous system. Also we find that, if practised enough, fairly complex sequences may be encoded as a small number of cortical representations. This appears to apply to language generation as well, especially for spoken language. Our conversations are full of cliches and sayings (“at the end of the day”). Within the cortex itself, brain activity appears to cascade from higher levels to lower levels but with feedback between the layers during language generation, e.g. we translate a representation of an object into a series of sounds then a series of muscle activations.
So in our brain:
- There is structure in language (otherwise it would be incomprehensible).
- Comprehension arrives through shared conventions.
- These shared conventions are fuzzy – as they are shaped through social use different contradictory rules may apply at the same time.
- The structure of language at least partially reflects preferred methods of information representation and organisation in the human cortex.
This is just a quick run through of some of my thinking on this point. What you should take home is that language models are useful in many engineering applications but they are not “artificial intelligence” as believed by many.
