Ever since reading On Intelligence, I’ve been a fan of Jeff Hawkins. It seems he’s often dismissed or overlooked because he operates outside the typical academic community (he publishes in Open Access journals). However, his ideas have held up over the decades, and his thinking is often ahead of the curve.
Given this, I was excited to find a talk he gave at MIT’s Centre for Brains, Minds and Machines in 2017. The talk is below. It’s part of an amazing series of talks from a variety of the world’s top minds, on various aspects of our minds. This post deals with the first part of the talk on his models of sequence memory. I may write another post that focuses on the “allocentric” conditioning.
The talk catches up on the research Jeff has been doing since the publication of On Intelligence in 2004. Fair play to the man, he’s spent his Palm fortune on setting up a small, 12-person, private-research laboratory (Numenta) with the aim of reverse engineering the brain.
On Intelligence left us with a focus on the neo-cortex. This is a two-dimensional sheet with a repeated 6-layer structure. The structure of the neo-cortex is remarkably conserved across the sheet. This suggests it repeats a common structure to perform many different functions. It’s reminiscent of looking at a microchip under a microscope and seeing millions of identical logic gates.
We also have an idea that the neo-cortex appears to embody a processing hierarchy. Early layers detect simple local features that are passed to higher layers for the detection of more complex global features that are then used to detect objects. This provides the theory behind convolutional neural network architectures.
Jeff’s talk touches on how this might not actually be the whole story.
Cortical Columns
Jeff’s investigations begin with the cortical column, and in particular with the function of the layers within the column. The concept of a cortical column came out of the seminal work by Hubel and Wiesel on vision. They found that areas of the cortical sheet in the early vision areas (e.g. V1) had a particular receptive field, and there appeared to be a one-to-one mapping between a visual receptive field and an area of cortex. This organisation was found to exist in other sensory modalities (but some of this is debated). There have been several theories of cortical function based on the idea of cortical columns, including the Canonical Microcircuits for Predictive Coding from Bastos et al. There are some points that most agree on:
- The cortex appears to work on predictive principles – it appears to model the world and use these models to predict incoming sensory information.
- The cortex is predicting within time. This applies to both incoming sensory information and outgoing muscle activation. Prediction within time may be thought of as modelling temporal sequences.
- The cortex appears to apply a common approach to different modalities. There does indeed appear to be a common algorithm. This may be seen in the manner that different parts of the brain may quickly adapt themselves to different sensory input, e.g. following injury.
- There appears to be some common organisational properties – e.g. multiple vertical layers and horizontal extension relating to function (e.g. representing a particular receptive field).
- Feedback and lower sub-structures are a vital part of the brain.
Prediction & The Pyramidal Cell
Jeff has some interesting thoughts on prediction. He presents a theory based on the structure of the pyramidal cell:
The theory is built on the observation that only about 10% of the synapses in a pyramidal neuron are proximal (near the centre – shown in green above), with the remaining 90% being distal (at the bottom towards the ends of the dendrites and at the top). The proximal synapses provide the classical receptive field for the neuron, i.e. the couplings that cause it to fire in a relatively feed-forward manner. It’s the distal synapses that are thought to be important for prediction: these synapses depolarise the cell and place in a “predictive” state that modulates the firing of the neuron. In effect signals received via the distal synapses act to provide a “context” for the firing of the cell, and that “context” operates in a probabilistic manner. If a single cell has thousands of synapses, then the cell can “predict” its firing in hundreds of independent contexts. The activity at the distal dendritic synapses is used to “predict” somatic spiking. Depolarisation means that a neuron is more likely to fire, and when a neuron fires it inhibits its neighbours, making these less likely to fire. This is important, as it provides a mechanism for building up patterns over time. It also reflects the scientific evidence on cortical column activation. The upper distal dendrites of the pyramidal neuron in the figure above have synapses that provide feedback and the lower distal dendrites provide context.
The paper setting out this theory can be found here.
Sparse Activations
Of particular interest was the theory of sparse activations:
This is based on the observation that in one layer of a cortical column, with about 5000 neurons, only about 2% of the cells (e.g. 100) are active at one time. This is the so-called “sparse” activation.
Sparse activation makes sense from an engineering perspective – it helps to minimise energy use. If 98% of the cells needed to fire this would take an awful lot of Haribo to provide simple cognition.
Aside: there are debates about whether “cortical columns” really exist as discrete units of neural computation. It is noted that some “cortical columns” have 100s of neurons whereas Jeff’s cortical column here has 1000s.
This was of interest because with this level of activation, populations of randomly chosen neurons have minimal overlap – they are approximately orthogonal. A particular pattern of activation can be determined by sampling the activity of between 10 to 20 neurons out of the 5000. As the patterns are approximately orthogonal, many patterns can be simultaneously active. This provides robustness – a cell can be distally coupled to 10-20 neurons that uniquely identifies/predicts a particular pattern despite other sets of neurons within the larger population being active. Robustness can also be improved by providing redundancy – going from 10 to 20 neurons within the distal synaptic couplings greatly increases the chances of correctly detecting a particular wide pattern of activation within a neuron population. Unions of cellular activity reflect uncertainty – e.g. the greater the number of simultaneously active orthogonal patterns, the greater the uncertainty.
The Hierarchical Temporal Memory (HTM) Model
Jeff and his team have built a software model of this activation:
The cell’s dendrites are modelled as a set of threshold coincidence detectors. If the number of active synapses in a row above exceeds a threshold, then a signal is passed to the neuron (in an OR manner with regard to other rows), which affects the feedforward activation.
Sequence Memory
This basis set up is used to support a theory of sequence memory.
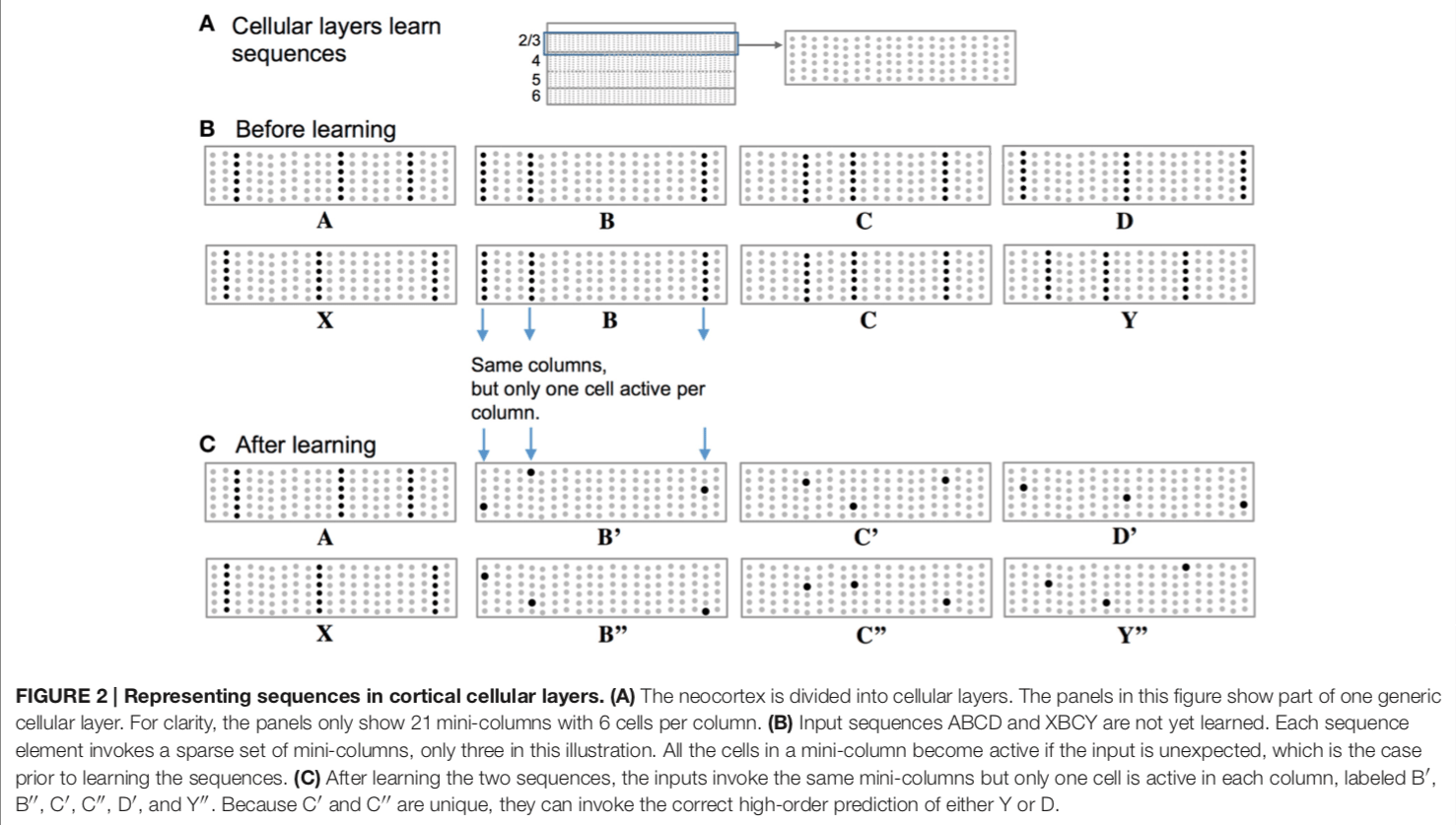
In the above example, a layer within a cortical column (such as layer 2/3 here) is considered to comprise a number of “mini-columns”. These mini-columns are a collection of neurons within a layer (e.g. each dot is a neuron and the solid dots represent firing of that neuron).
Before learning, a particular set of cell activations across these mini-columns represent a particular feature. In the example, “A” is represented by the activations of all the neurons in the 3rd, 12th, and 18th mini-columns.
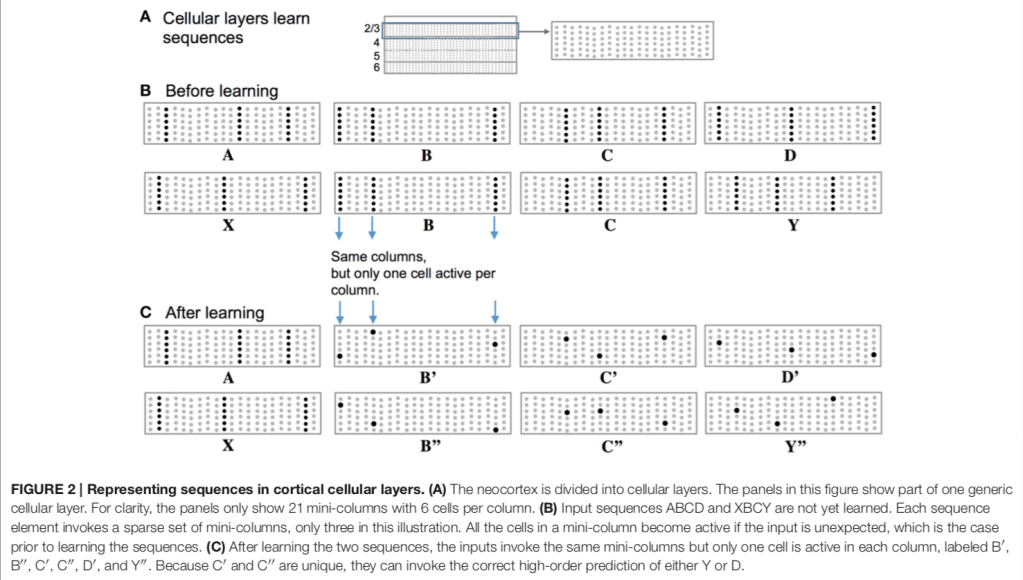
After learning, the temporal context acts to select particular neurons within each mini-column of the “before learning” representations. For example, the previous firing of “A” or “X” provides a distal dendritic (and temporal) context that makes certain cells more likely to fire. Basically, this theory has different sub-representations that are related to a more general parent representation that are selected based on context. A predicted input leads to a very sparse pattern of cell activation that is unique to a particular element, at a particular location, in a particular sequence.
In this theory, the basal (base of the neuron but not part of the distal portions) portions of an neuron learn and store transitions in sequences of activity. These are detected based on the activation of neighbouring columns and cells.
There are also two levels of prediction. Feedback prediction occurs via apical dendrites (those at the top). This can predict or bias towards multiple possible inputs (e.g. B’, C’ and D’ above). Multiple predictions are possible due to the sparse representations. Lateral connections to basal dendrites provide temporal prediction as Figure 3 above.
Learning Rules
The model put forward by the theory require a learning rule with two aspects.
- Learning occurs by growing and removing synapses within a local population of neurons.
- Hebbian learning and synaptic change need to be modelled at the level of dendritic segments not the whole neuron.
They have a nice way of modelling synaptic plasticity. They use a scalar synaptic permanence value that indicates a strength of the synapse. A threshold is set to generate a “synapse exists” binary value – if the threshold is 0.3 and a synaptic permanence value is 0.4 there will be a synapse, but this synapse is more liable to be lost than one with a synaptic permanence value of 0.7.
Related Work
The simulation results and general models remind me of the work of Sophie Deneve et al (“The Brain as an Efficient and Robust Adaptive Learner”). This is interesting: both teams are coming at the same problem from different directions, and arrive at similar answers (independently it seems). For example, the statistics on robustness to noise and neuron “death” are similar, and these appear to match experimental evidence from the brain. Work similar to this is cited in the Hawkins / Ahmad paper – but it is explained how the work of the French team is typically looking at a lower level of detail, incorporating continuous time models.
It also reminds me of the classic “Predictive Estimator” entities of the classic Rao and Ballard paper, only in this case the “Estimator” is modelled at the individual neuron level.
