In this post, I imagine a set of very simple “intelligent” entities: Dave and Susan.
Intelligence
Intelligence is often defined as:
the ability to act appropriately in response to a state of the world.
Most focus on “appropriately”. But “appropriately” is far too subjective for my liking. Let’s ditch it for now. We can always let an algorithm work out what “appropriately” means for a given environment.
So, let’s just define intelligence as:
the ability to act in response to a state of the world.
Using this as a starting point, we can consider a simple intelligence and see if it tells us anything about bigger intelligences. We’ll call our first simple intelligence “Dave”.
State
In the simplest of cases, there is but one state of the world to measure. This may be “something” rather than “nothing”. Dave can measure the state (e.g. he might have some form of mechano-chemical contraption to sense the world). We can represent his measurement of the world with a binary variable 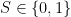
Action
Our primitive being also has only one way of acting in the world. They can “act” or they cannot “act”. We can think of this as the signal to one big snail-like muscle. We can represent it with a binary variable 
Let’s consider a case where Dave acts as he pleases. The probability of taking an action at any point in time is 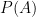
As our action is a binary variable, we can more specifically consider the cases of 
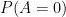

If Dave acts at random we can set 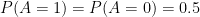
State, Action
Now let’s consider acting based on the state. We can consider another probability, that of the action given the state 
As we have binary variables, we have four different action-state combinations, 
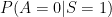


In certain cases, we might define

Now, regardless of appropriateness, we can only start to have intelligence when 
Through Bayes Theorum, we can rewrite

For our inequality to hold, we see that 


This makes nice poetic sense – if our actions didn’t make a difference we couldn’t be here.
Sense More
Some interesting things happen when we consider expanding our sensory repertoire.
Let’s consider that Dave has some mutated offspring. Let’s call that offspring “Susan”. Imagine that the offspring arises after a cosmic ray hits Dave’s DNA. The mutation causes Susan to be born with an additional sensory organ. Susan can sense the original state of the world, like Dave. For ease, let’s call this 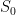
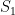

Are We Any Cleverer?
Now we can sense two states, does that make us any cleverer?
As before, we only make gains if the probability of acting differs given the two states, as compared to the one state: 

Applying Bayes Theorem again, we get:

For the last inequality to hold, we need 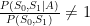
Independence
If our measured states are independent, we can start applying some mathematical tricks.
For example, if
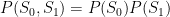
Conditional Independence
If our measured states are also conditionally independent, we can apply another trick.
Conditional independence means that two events are independent given, or conditional on, another third event. If the two measured states are independent given the action, we can say:
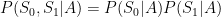
and

The latter expression is interesting. It says, if conditional independence holds, that the probability of our new state given an action and an old state is equal to just the probability of our new state given the action. We can think of this as saying that our action becomes the memory sink for our states or that the previous state only affects our current state through the medium of the action.
Simplifying
If we are able to say that the two measured states are both independent and conditionally independent given the action, then we can rewrite 

In this case, for 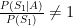
In this case, we also see that we can reuse our old determination for 
Feedback
It is also interesting to look at the expressions 

Well 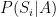
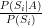
Bayesian Networks
In our simple toy configuration, the action A is both a “collider” and a “fork” depending on the direction we are considering. The “fork” pattern provides for conditional independence on the “fork”; in our case, looking from A backwards, A is the “fork” and

Looking forwards, from the state to the action, as long as
Separating Our States
If we know that
We can make a start by trying to make our states linearly independent. We can do this by transforming them such that they are uncorrelated. Two random variables are uncorrelated if their covariance is zero. We can make our states linearly independent by applying principal component analysis. We can consider a two state vector 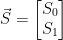
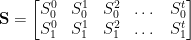
We can then use this to compute a covariance matrix, and then apply principal component analysis to develop a transformation matrix 

There is a great post from Stanford’s Computer Science department explaining this here.
Note: that PCA and the aforementioned post assume data with zero mean – our binary data has a non-zero mean so we require an additional mean-removal pre-processing step. It also makes sense to “whiten” any transformed data. This divides by the square roots of the eigenvalues such that the changes have unit (e.g. 1) variance.
More Action
Let’s consider another mutation scenario. Imagine the cosmic ray hits Dave and the mutated sprog of Susan has two muscles rather than one. She can thus make two movements. Let’s call these 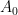
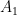
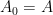

Let’s also assume that Susan can control her new multi-muscles independently. This isn’t too unrealistic at this simple stage.
In a first scenario considering just a single state 


In a second scenario, we can imagine a constraint – only one of 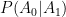


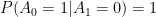
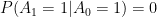

IF (and it’s actually an unlikely IF), our state S and our action

IF independent – 

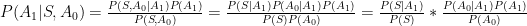

The problem is we have neither independence nor conditional independence on

It’s a shame because the simplified expression could have given us an expression to update our models for one state and one action, when an additional action is added.
If the conditions did hold, the probability of selecting an action from the new group would be dependent on how the actions interact – set by 
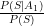
A similar expression could be drawn up for the first action
If we were looking at how the probability of the old action changes, we would see that the new probability would be set by the existing non-unity factor for the old action – 
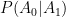
Cutting the Cord
When considering the probability of the new second action in the context of the original first action 
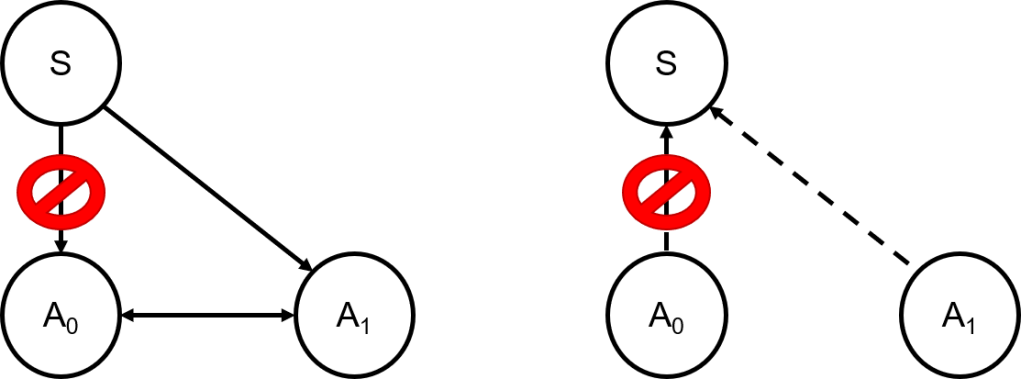
When considering the probability of the original first action in the context of the new second first action 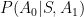

Can we do this?!
Now things get interesting.
You probably know that correlation 
But.
There are two things to consider.
First, if two random variables are jointly normally distributed a correlation of 0 does imply independence. This is interesting because the central limit theorem indicates that as we increase the number of samples, we may get something resembling a normal distribution.
Second, we can represent a function with a Taylor polynomial. This requires a sufficiently “well-behaved” function, which means that the function needs to be sufficiently continuously differentiable (at least up to the polynomial degree being applied). It indicates that complex functions can be imperfectly approximated using different levels of complexity. We can start we a linear approximation and progressively add higher order terms to get closer to the real function. This is shown for 
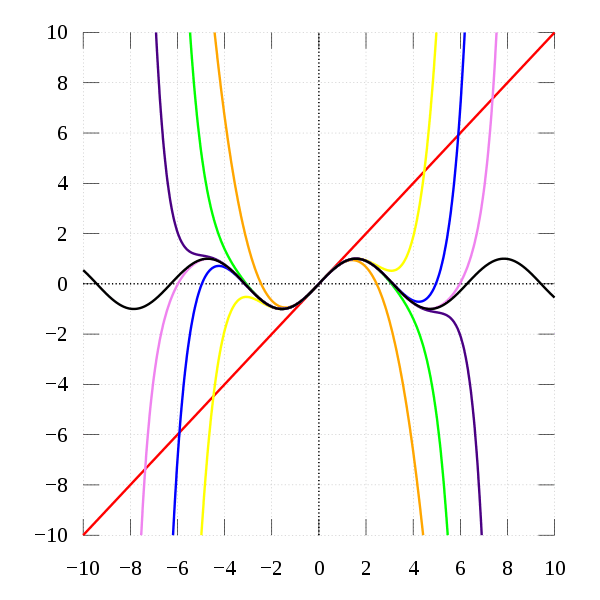
It may be that we can provide approximations to independence at different levels of complexity. The details of this can be looked at in a later post.
Looking Both Ways
So in this post, we looked at some simple state-action mappings.
We found that when we add additional states to control our actions, we could chain probabilities and develop rules for testing whether our additional information actually makes a difference to our actions.
It turns out that it doesn’t matter whether we look at things from the perspective of states or actions, similar probability rules apply. In both cases, when we extend the space of states or actions, we can use simple update rules if we can somehow ensure independence among the variables that form our context.
When considering an action in the context of multiple states, 
When considering an action that may be influenced by other actions and a state,
We also realised that we probably don’t have independence out-of-the-box. But there are hints that we can apply mathematical operations that result in an approximation of independence. In future posts we’ll consider whether these approximations are suitable for navigation within the real-world.
