Or the stuff no one tells you that is actually quite hard.
Recently I’ve been playing around with the last 15 years of patent publications as a ‘big data’ source. This includes over 4 million individual documents. Here I thought I’d highlight some problems I faced. I found that a lot of academic papers tend to ignore or otherwise bypass this stuff.
Sentence Segmentation
Many recurrent neural network (RNN) architectures work with sentences as an input sequence, where the sentence is a sequence of word tokens. This introduces a first problem: how do you get your sentences?
A few tutorials and datasets get around this by providing files where each line in the file is a separate sentence. Hence, you can get your sentences by just reading the list of filelines.
In my experience, the only data where file lines are useful is code. For normal documents, there is no correlation between file lines and sentences; indeed, each sentence is typically of a different length and so is spread across multiple file lines.
In reality, text for a document is obtained as one large string (or at most a set of paragraph tags). This means you need a function that takes your document and returns a list of sentences: s = sent_tokenise(document).
A naive approach is to tokenise based on full stops. However, this quickly runs into issues with abbreviations: “U.S.”, “No.”, “e.g.” and the like will cut your sentences too soon.
The Python NLTK library provides a sentence tokeniser function out-of-the-box – sent_tokenize(text). It appears this is slightly more intelligent that a simple naive full stop tokenisation. However, it still appears to be cutting sentences too early based on some abbreviations. Also optical character recognition errors, such as “,” instead of “.”, or variable names, such as “var.no.1” will give you erroneous tokenisation.

One option to resolve this is to train a pre-processing classifier to identify (i.e. add) <end-of-sentence> tokens. This could work at the word token level, as the NLTK word tokeniser does appear to extract abbreviations, websites and variable names as single word units.
You can train the Punkt sentence tokenizer – http://www.nltk.org/api/nltk.tokenize.html#module-nltk.tokenize.punkt and https://stackoverflow.com/questions/21160310/training-data-format-for-nltk-punkt . One option is to test training the Punkt sentence tokenizer with patent text.
Another option is to implement a deep learning segmenter on labelled data – e.g. starting from here – https://hal.archives-ouvertes.fr/hal-01344500/document . You can have sequence in and control labels out (e.g. a sequence to sequence system). Or even character based labelling using a window around the character (10-12). This could use a simple feed-forward network. The problem with this approach is you would need a labelled dataset – ideally we would like an unsupervised approach.
Another option is to filter an imperfect sentence tokeniser to remove one or two word sentences.
Not All File Formats are Equal
An aside on file formats. The patent publication data is supplied as various forms of compressed file. One issue I had was that it was relatively quick and easy to access data in a nested zip file (e.g. multiple layers down – using Python’s zipfile). Zip files could be access as hierarchies of file objects. However, this approach didn’t work with tar files, for these files I needed to extract the whole file into memory before I could access the contents. This resulted in ‘.tar’ files taking up to 20x longer to access than ‘.zip’ files.
Titles
Related to sentence segmentation is the issue of section titles. These are typically set of <p></p> elements in my original patent XML files, and so form part of the long string of patent text. As such they can confuse sentence tokenisation: they do not end in a full stop and do not exhibit normal sentence grammar.

Titles can however be identified by new lines (\n). A title will have a preceding and following new line and no full stop. It could thus be extracted using a regular expression (e.g. “\n\s?(\W\s?)\n”).
Titles may be removed from the main text string. They may also be used as variables of “section” objects that model the document, where the object stores a long text string for the section.
As an aside, titles in HTML documents are sometimes wrapped in header tags (e.g. <h3></h3>). For web pages titles may thus be extracted as part of the HTML parsing.
Word Segmentation
About half the code examples I have seen use a naive word tokenisation that splits sentences or document strings based on spaces (e.g. as a list comprehension using doc.split()). This works fairly successfully but is not perfect.
The other half of code examples use a word tokenising function supplied by a toolkit (e.g. within Keras, TensorFlow or NLTK). I haven’t looked under the hood but I wouldn’t be surprised if they were just a wrapper for the simple space split technique above.
While these functions work well for small curated datasets, I find the following issues for real world data. For reference I was using word_tokenise( ) from NLTK.
Huge Vocabularies
A parse of 100,000 patent documents indicates that there are around 3 million unique “word” tokens.
Even with stemming and some preprocessing (e.g. replacing patent numbers with a single placeholder token), I can only cut this vocabulary down to 1 million unique tokens.

This indicates that the vocabulary on the complete corpus will easily be in the millions of tokens.
This then quickly makes “word” token based systems impractical for real world datasets. For many RNN system you will need to use a modified softmax (e.g. sampled or hierarchical) on your output, and even these techniques may grind to a holt at dimensionalities north of 1 million.
The underlying issue is that word vocabularies have a set of 50-100k words that are used frequently and a very long tail of infrequent words.
Looking at the vocabulary is instructive. You quickly see patterns of inefficiency.
Numbers
This is a big one, especially for more technical text sources where numbers turn up a lot. Each unique number that is found is considered a separate token.

This becomes a bigger problem with patent publications. Numbers occur everywhere, from parameters and variable values to cited patent publication references.
Any person looking at this quickly asks – why can’t numbers be represented in real number space rather than token space?
This almost becomes absurd when our models use thousands of 32 bit floating point numbers as parameters – just one parameter value can represent numbers in a range of -3.4E+38 to +3.4E+38. As such you could reduce your dimensionality by hundreds of thousands of points simply by mapping numbers onto one or two real valued ranges. The problem is this then needs bespoke model tinkering, which is exactly what most deep learning approaches are trying to avoid.
Looking at deep learning papers in the field I can’t see this really being discussed. I’ve noticed that a few replace financial amounts with zeros (e.g. “$123.23” > “$000.00”). This then only requires one token per digit or decimal place. You do then lose any information stored by the number.
I have also noticed that some word embedding models end up mapping numbers onto an approximate number range (they tend to be roughly grouped into linear structures in embedding space). However, you still have the issue of large input/output dimensions for your projections and the softmax issue remains. There is also no guarantee that your model will efficiently encode numbers, e.g. you can easily image local minima where numbers are greedily handled by a largish set of hidden dimensions.
Capital Letters
As can be seen in the list of most common tokens set out above, a naive approach that doesn’t take into account capital letters treats capitalised and uncapitalised versions of a word as separate independent entities, e.g. “The” and “the” are deemed to have no relation in at least the input and output spaces.

Many papers and examples deal with this by lowering the case of all words (e.g. preprocessing using wordstring.lower()). However, this again removes information; capitalisation is there for a reason: it indicates acronyms, proper nouns, the start of sentences etc.
Some hope that this issue is dealt with in a word embedding space, for example that “The” and “the” are mapped to similar real valued continuous n-dimensional word vectors (where n is often 128 or 300). I haven’t seen though any thought as to why this would necessarily happen, e.g. anyone thinking about the use of “The” and “the” and how a skip-gram, count-based or continuous bag of words model would map these tokens to neighbouring areas of space.
One pre-processing technique to deal with capital letters is to convert each word to lowercase, but to then insert an extra control token to indicate capital usage (such as <CAPITAL>). In this case, “The” becomes “<CAPITAL>”, “the”. This seems useful – you still have the indication of capital usage for sequence models but your word vocabulary only consists of lowercase tokens. You are simply transferring dimensionality from your word and embedding spaces to your sequence space. This seems okay – sentences and documents vary in length.
(The same technique can be applied to a character stream to reduce dimensionality by at least 25: if “t” is 24 and “T” is 65 then a <CAPITAL> character may be inserted (e.g. index 3) “T” can become “3”, “24”.)
Hyphenation and Either/Or
We find that most word tokenisation functions treat hyphenated words as single units.

The issue here is that the hyphenated words are considered as a further token that is independent of their component words. However, in our documents we find that many hyphenated words are used in a similar way to their unhyphenated versions, the meaning is approximately the same and the hyphen indicates a slightly closer relation than that of the words used independently.
One option is to hope that our magical word embeddings situate our hyphenated words in embedding space such that they have a relationship with their unhyphenated versions. However, hyphenated words are rare – typically very low use in our long tail – we may only see them one or two times in our data. This is not enough to provide robust mappings to the individual words (which may be seen 1000s of times more often).
So Many Hyphens
An aside on hyphens. There appear to be many different types of hyphen. For example, I can think of at least: a short hyphen, a long hyphen, and a minus sign. There are also hyphens from locale-specific unicode sets. The website here counts 27 different types: https://www.cs.tut.fi/~jkorpela/dashes.html#unidash . All can be used to represent a hyphen. Some dimensionality reduction would seem prudent here.
Another answer to this problem is to use a similar technique to that for capital letters: we can split hyphenated words “word1-word2” into “word1”, “<HYPHEN>”, “word2”, where “<HYPHEN>” is a special control character in our vocabulary. Again, here we are transferring dimensionality into our sequence space (e.g. into the time dimension). This seems a good trade-off. A sentence typically has a variable token length of ~10-100 tokens. Adding another token would seem not to affect this too much: we seem to have space in the time dimension.
A second related issue is the use of slashes to indicate “either/or” alternatives, e.g. “input/output”, “embed/detect”, “single/double-click”. Again the individual words retain their meaning but the compound phrase is treated as a separate independent token. We are also in the long tail of word frequencies – any word embeddings are going to be unreliable.

One option is to see “/” as an alternative symbol for “or”. Hence, we could have “input”, “or”, “output” or “embed”, “or”, “detect”. Another option is to have a special “<SLASH>” token for “either/or”. Replacement can be performed by regular expression substitution.
Compound Words
The concept of “words” as tokens seems straightforward. However, reality is more complicated.
First, consider the terms “ice cream” and “New York”. Are these one word or two? If we treat them as two independent words “ice cream” becomes “ice”, “cream” where each token is modelled separately (and may have independent word embeddings). However, intuitively “ice cream” seems to be a discrete entity with a semantic meaning that is more than the sum of “ice” and “cream”. Similarly, if “New York” is “New”, “York” the former token may be modelled as a variation of “new” and the latter token as entity “York” (e.g. based on the use of “York” elsewhere in the corpus). Again this seems not quite right – “New York” is a discrete entity whose use is different from “New” and “York”. (For more fun also compare with “The Big Apple” – we feel this should be mapped to “New York” in semantic space, but the separate entities “New”, “York”, “The”, “Big”, “Apple” are unlikely to be modelled as related individually.)
The case of compound words probably has a solution different from that discussed for hyphenation and slashes. My intuition is that compound words reflect features in a higher feature space, i.e. in a feature space above that of the individual words. This suggests that word embedding may be a multi-layer problem.
Random Characters, Maths and Made-Up Names
This is a big issue for patent documents. Our character space has a dimensionality of around 600 unique characters, but only about 100 are used regularly – again we have a longish tail of infrequent characters.

Looking at our infrequent characters we see some patterns: accented versions of common characters (e.g. ‘Ć’ or ‘ë’); unprintable unicode values (possibly from different character sets in different locales); and maths symbols (e.g. ‘≼’ or ‘∯’).
When used to construct words we end up with many variations of common word tokens (‘cafe’ and ‘café’) due to the accented versions of common characters.
Our unprintable unicode values appear not to occur regularly in our rare vocabulary. It thus appears many of these are local variations on control characters, such as whitespace. This suggests that we would not lose too much information with a pre-processing step that removed these characters and replaced them with a space (if they are not printable on a particular set of computers this suggests they hold limited utility and importance).
The maths symbols cause us a bit of a problem. Many of our rare tokens are parts of equations or variable names. These appear somewhat independent of our natural language processing – they are not “words” as we would commonly understand them.
One option is to use a character embedding. I have seen approaches that use between 16 and 128 dimensions for character embedding. This seems overkill. There are 26 letters, this is multiplied by 2 for capital letters, and there are around 10 common punctuation characters (the printable set of punctuation in Python’s string library is only of length 32). All the unicode character space may be easily contained within one real 32 bit floating point dimension. High dimensionality would appear to risk overfitting and would quickly expand our memory and processing requirements. My own experiments suggest that case and punctuation clustering can be seen with just 3 dimensions, as well as use groupings such as vowels and consonants. One risk of low dimensional embeddings is a lack of redundant representations that make the system fragile. My gut says some low dimensionality of between 1 and 16 dimensions should do. Experimentation is probably required within a larger system context. (Colin Morris has a great blog post where he looks at the character embedding used in one of Google Brain’s papers – the dimensionality plots / blogpost link can be found here: http://colinmorris.github.io/lm1b/char_emb_dimens/.)
What would we like to see with a character embedding:
- a relationship between lower and upper case characters – preferable some kind of dimensionality reduction based on a ‘capital’ indication;
- mapping of out of band unicode characters onto space or an <UNPRINTABLE> character;
- mapping of accented versions of characters near to their unaccented counterpart, e.g. “é” should be a close neighbour of “e”;
- clustering of maths symbols; and
- even spacing of frequently used characters (e.g. letters and common punctuation) to provide a robust embedding.
There is also a valid question as to whether character embedding is needed. Could we have a workable solution with a simple lookup table mapping?
Not Words
Our word tokenisation functions also output a lot of tokens that are not really words. These include variable names (e.g. ‘product.price’ or ‘APP_GROUP_MULTIMEDIA’), websites (e.g. ‘www.mybusiness.com’), path names (e.g. ‘/mmt/glibc-15/lib/libc.so.6’, and text examples (‘PεRi’). These are often: rare – occurring one or two times in a corpus; and document-specific – they often are not repeated across documents. They make up a large proportion of the long-tail of words.
Often these tokens are <UNK>ed, i.e. they are replaced by a single token that represents rare words that are not taken into account. As our token use follows a power law distribution this can significantly reduce our vocabulary size.
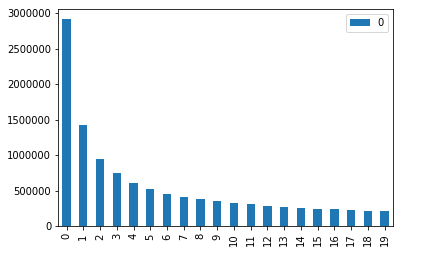
For example, the plot above shows that with no filtering we have 3 million tokens. By filtering out tokens that only appear once we reduce our vocabulary size by half: to 1.5 million tokens. By filtering out tokens that only appear twice we can reduce our dimensionality by another 500,000 tokens. Gains fall off as we up the threshold, by removing tokens that appear fewer than 10 times, we can get down to a dimensionality of around 30,000. This is around the dimensionality you tend to see in most papers and public (toy) datasets.
The problem with doing this is you tend to throw away a lot of your document. The <UNK> then becomes like “the” or “of” in your model. You get samples such as “The <UNK> then started to <UNK> about <UNK>”, where any meaning of the sentence is lost. This doesn’t seem like a good approach.
The problem of <UNK> is a fundamental one. Luckily the machine learning community is beginning to wake up to this a little. In the last couple of years (2016+), character embedding approaches are gaining traction. Google’s neural machine translation system uses morpheme-lite word ‘portions’ to deal with out of vocabulary words (see https://research.google.com/pubs/pub45610.html). The Google Brain paper on Exploring the Limits of Language Modelling (https://arxiv.org/pdf/1602.02410.pdf) explores a character convolutional neural network (‘CharCNN’) that is applied to characters (or character embeddings).
What Have We Learned?
Summing up, we have found the following issues:
- sentence segmentation is imperfect and produces noisy sentence lists;
- some parts of a document such as titles may produce further noise in our sentence lists; and
- word segmentation is also imperfect:
- our vocabulary size is huge: 3 million tokens (on a dataset of only 100,000 documents);
- numbers are a problem – they are treated as separate discrete units, which seems inefficient;
- the concept of a “word” is fuzzy – we need to deal with compound words, hyphenation and either/or notation;
- there are different character sets that lead to separate discrete tokens – e.g. capitals and accented letters – when common underlying tokens appear possible; and
- non-language features such as equations and variable names contribute heavily to the vocabulary size.
Filtering out non-printable unicode characters would appear a good preprocessing step that has minimal effect on our models.
Character embedding to a low dimensional space appears useful.
Word/Character Hybrid Approach?
Looking at my data, a character-based approach appears to be the one to use. Even if we include all the random characters, we only have a dimensionality of 600 rather than 3 million for the word token space.
Character-based models would appear well placed to deal with rare, out-of-vocabulary words (e.g. ‘product.price’). It also seems much more sensible to treat numbers as sequences of digits as opposed to discrete tokens. Much like image processing, words then arise as a layer of continuous features. Indeed, it would be relatively easy to insert a layer to model morpheme-like character groupings (it would appear this is what the CNN approaches are doing).
The big issue with character level models is training. Training times are increased by orders of magnitude (state of the art systems take weeks on systems with tens of £1k graphic cards).
However, we do have lots of useful training data at the word level. Our 50 most common unfiltered word tokens make up 46% (!) of our data. The top 10,000 tokens make up 95% of the data. Hence, character information seems most useful for the long tail.
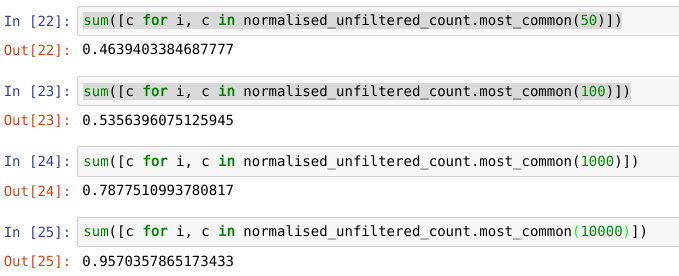
This then suggests some kind of hybrid approach. This could be at a model or training level. The 95% of common data would suggest we could train a system using common words as ground truth labels and configure this model to generalise over the remaining 5%. Alternatively, we could have a model that operates on 10k top tokens with <UNK>able words being diverted into a character level encoding. The former seems preferable as it would allow a common low-level interface, and the character information from the common words could be generalised to rare words.
I’ll let you know what I come up with.
If you have found nifty solutions to any of these issues, or know of papers that address them, please let me know in the comments below!
