
I recently treated myself to one of these:

And it got me thinking again about how all (most) computer vision is wrong (or at least horribly inefficient).
Why?
To get the Oculus Quest 2 (or any virtual reality – VR – headset) to work with a desktop computer, you need a hugely power gaming specification, a £500+ graphics card and at least a 300Mbps transfer link. This is because the Quest 2 has an Liquid Crystal Display (LCD) screen with 1832×1920 pixels per eye running at 90 Hz. This looks lovely, and really helps with the “reality” bit in VR. However, to provide the eyes with visual information you need 2x1832x190=7034880 pixels. That’s 7 million. If there are three colour channels at 8-bit per channel, that’s 56Mbits (7Mbytes) per frame. If you want snazzier colour depth with High Dynamic Range (HDR) and Wide Colour Gamut (WCG), times that number by 2. Now, 90 Hz means 90 frames per second, so we have 90*56=5040Mbits/second (~630Mbytes/second). This is only the information on screen – virtual worlds are many times bigger than the current screen view, meaning you are quickly looking at processing rates of GB/second. “Old” Wi-Fi at 54Mbps looks quaint.
It gets worse. VR worlds need to work out what value each of those pixels needs at any one time sample. Computer vision often looks at this task at a pixel level. It’s like trying to draw a picture by choosing which pen to colour all the squares of small French-style engineering graph paper at a rate of 90 times per second.
Something here doesn’t sit right with me. Yes, you can wait for Moore’s Law to catch up and provide the computing bandwidth for free, but it seems a lot of hard work. And nature is lazy.
The Problem
The problem is that computer vision treats visual information as sets of frames that are changed very quickly before our eyes to create the illusion of motion. Each frame is a two-dimensional “photo” of the world.

Frames assume we can see all the pixels we are being shown at one time. This isn’t true. We only “see” a small postage stamp sized region of the world in “high-definition” at any one time. This is because there is only a small section of the retina, the fovea, that has enough light sensors to view colour in high detail (i.e. with high visual acuity). The decline in vision is steep (exponential actually).

A rule of thumb (avoid the pun) is that we only see in high detail a portion of the visual scene that is about the size of your thumbnail with your hand outstretched.
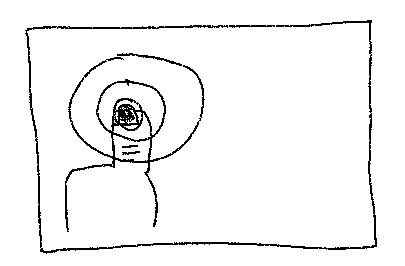
We actually “see” more like this:
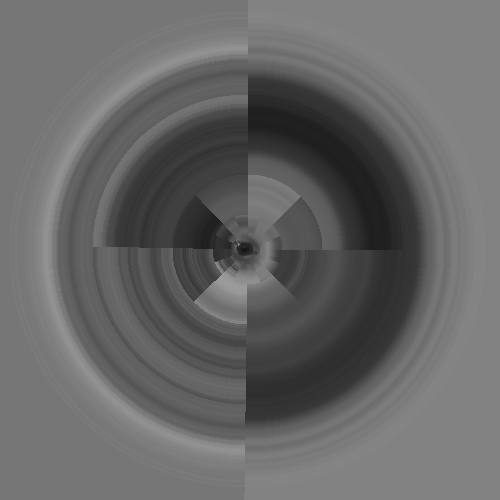
Gaze
If we can only see a small portion of the world in detail at any one time, how come we see what looks like a photo at any one time?
Enter magicians.

Our eyes are actually in constant motion. Where we look is called gaze. It’s a process over time. Visual perception happens over time, not all at once.
This is why magic works. We think we are seeing the whole scene in perfect detail. But really we are only attending to a small part of the scene at any one time. This disconnect between what we believe and what we perceive is the crack that allows magic in. During close-up magic, you are actually automatically mainly attending to the (often attractive) face of the magician opposite rather than the hands of the magician. Magicians are extremely skilled in diverting your attention, the high detailed perception via the fovea, from where the trick is being performed. Magic seems “magic” because your expectations are built from your beliefs of the scene. You haven’t perceived the actual overly complex causal reality of the world.
Gaze is actually a pretty primitive component of our brains, hard-wired into complex circuits of attention and reward (such as those containing the substantia nigra). The cunning thing about gaze is our brains have access to the signals that are used to instruct eye and head (i.e. muscle) movements. The neuroscience evidence suggests that we are constantly predicting what we expect to see at the location our eyes are instructed to look at. Basically our brains are a big simulation of the outside world, but a simulation that is constantly updated to match sensor data from that world. In fact, surprise and fear are possibly shades of the same primitive control system – an indication that we need to attend as the evidence from the outside world isn’t matching our predictions.

As shown above, recordings of human gaze actually resemble something more like a graph structure. We typically randomly sample a portion of the scene we are currently facing, guiding this random sampling by peripherally perceived low-resolution changes in light, colour or shape. When we see a feature we recognise, like part of a face, we tend to latch onto it, view all around it, then jump to a prediction of where we believe a corresponding feature will be, such as another eye, mouth or nose. Our guesses are never quite right, so we adjust, find the feature, view it again then perform another jump. These jumps are known as “saccades”. Machine learning practitioners and mathematicians will rejoice, gaze trails look a lot like stochastic optimisation.
It should also be noted that gaze happens in time. We can’t look at all positions, the nodes of the gaze graph, at the same time (because: the laws of physics). So even a static scene is built dynamically via chains of probability. Indeed, it’s photos, pictures and video frames that are unusual in the natural world. We very often forget this, as our tools are static (e.g. this blog post, or the piece of paper I write on).
A Solution
So you can begin to see why I am morally offended by the direction of travel so far for VR. Our brains are laughing at us.
So what would computer vision look like, if it took a more brain-like approach?
Pictures would not exist at a single time. They would be created over time. They would form like drawings or paintings, with detail being developed in different small areas of a working frame, all guided by different predictive patterns at different scales. You would “grow” a photo.
Likewise, a key element of AR and VR vision would need to involve predictive models of gaze. If we can channel Pareto and accurately predict 80% or so of our actions based on simple (linear) models of behaviour (e.g., look at moving things), we don’t need 90 frames per second at Ultra High Definition for each eye. At any one time, we only need high resolution and detail for the very small portion of the world we are currently looking at. It turns out we can actually get pretty close in our predictions by using coarse macro models of the world. If we get things wrong, we can adjust in time. And, as vision happens in time, we just need to be faster than the eye in working out where we are looking.
We need engineers to be magicians.
