Recently I got to thinking about statistics and determinism. By statistics I mean the study of sets of data, typically obtained by measurement across a set of measurements or a population of “things”. By determinism I mean processes that always have the same output for the same input. Often in engineering they are presented as opposing: statistical mechanics operates over populations of (normally microscopic) entities where the population level descriptions have an inherent uncertainty (often represented as a probability); deterministic mechanics often drops the “deterministic” – if an object has a certain velocity or acceleration we can always predict where it will end up.
The Statistical Century
Now at the turn of the 20th century quantum physics upended much of this nice dichotomy. It was expected that entities at ever smaller scales would follow the deterministic Newtonian mechanics studied for several centuries. They didn’t. It turned out we could only make statistical inferences. We had to bring in wave functions and probabilities and could not guarantee where anything could be.
The 20th century saw the rise of statistics. Increasingly sophisticated data collection and processing methods, including the development of the computer, meant that we started to compute over data. However, computers are deterministic machines – stick the same code and data in, get the same code and data out. The fragmentation and specialisation of scientific enquiry meant that medicine and biology went one way, whereas engineering went another.
The rise of (tractable) neural networks and methods of training over the last 5-10 years has shaken up a lot of assumed wisdom when it comes to computation. Neural networks are still deterministic, same data in, same data out (via many linear operations in parallel and series) but they operate over large scale data sets. This means statistics has crept in via the back door into computing. While it has always hidden in the background, via fields such as probabilistic quantum mechanics and Bayesian logic, it has never really been explicitly taught as “the way of doing things” in engineering.
But. Neural networks currently struggle with “explainability”, working out what is going on. Actually, this is a misnomer – we can explain exactly what is going on in the form of the path of linear operations and non-linearities. The problem is the level of explanation. We need a statistical explanation, an explanation over a population based on population data.
Batch Normalisation
I got thinking more about this when I was looking at batch normalisation within neural networks (e.g., as used in ResNet). Data is normalised by subtracting a mean and dividing by a variance:
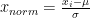
Where the mean and variance are determined based on a “batch” of data.
I’ve always felt this was a bit sneaky. It came in as a fudge based on image data input but has been taken up in several architectures. It means that during training you are normalising based on mini-batches but during inference you normalise using population means and variances. This is bringing statistics in via the back door.
Can We Mix and Match?
This raises the important question: are neural networks statistical or deterministic?
The answer appears to be that this isn’t a real question – the distinction is in our heads.
I’d argue that the interpretation of statistical as “unpredictable” or “probabilistic” is compatible with deterministic processes. They key is distinguishing between deterministic and perfect knowledge.
A process can be deterministic but our knowledge of it can be incomplete. For example, imagine a single pixel camera pointed at a candle. The camera is deterministic. The candle is deterministic. But we cannot know or control electronic noise or turbulence in the air. Hence, there will not be a perfect measurement of the candle by the camera – sometimes when the flame is lit the camera may not output a detection of light and sometimes when the flame is not lit the camera may output a spurious detection reading. However, there may be patterns over the population of measurements – statistical patterns. It’s not simply a case of saying we don’t know, yes – we don’t know 100% that the candle is lit from a positive camera output but if over 100 measurements the candle being lit and the positive camera outputs both occur 95 counts out of 100, then we can be 95% sure as a guess. This is much better than being 0% sure. The problem comes in mapping the logic of language – “knowing” or “not knowing” – that appears to be a binary selection to an actual process that is not binary, but is close to being binary. Language is not able to express the lower level nuance. This is because language is a discrete action. We can say we know “a little” or “a lot”, but our brains appear to process these as modifiers to a binary “know” rather than a true probabilistic representation.
So what are we saying when we say a process or thing is probabilistic or statistical? We are saying there are patterns over measurements but we can never predict any one measurement perfectly. Determinism is sometimes seem as opposing this because it is interpreted as concentrating on the latter part of this definition, it is seen as saying we can predict any one measurement perfectly. But the issue is not with the deterministic mechanics, it is with our omniscience – we cannot know precisely or exactly the conditions prior to any one measurement, we can only know a subset of things. Experimental error is just a way of saying there are other things at work we are unaware of.
