I’ve often been struck by the inflexibility of neural networks. So much effort goes into training huge billion parameter models, but these all have fixed sized inputs and outputs. What happens if you need to add another input or output?
I was thinking about this in the context of the simple matrix algebra of neural networks. Underneath everything you often have the simple equation:
y = Ax
Where y is a m by 1 vector of outputs, x is a n by 1 vector of inputs and A is a m by n matrix. Even complicated multi-dimensional convolutional mappings can often be flattened and rearranged into this form (just with really long vectors – this is actually how many graphical processing units actually compute things under the hood). A is the important “learnt” bit where the weights of the mapping between x and y are stored. We work out A by training the neural network using (x, y) pairs.
Of course, to model complex non-linear functions we need to stack up multiple neural networks. But each of these works according to a set of linear weights, with a non-linearity added to the output. One of the most popular non-linearities is the RELU (REctified Linear Unit), which just sets values below zero to zero and passes through positive values. The importance of the non-linearity appears to be to “break” the cascade of linear models, as opposed to doing anything fancy.
Here’s just some thoughts (possibly incorrect in some way) on how we can extend the input and output of neural networks based on some simple matrix partitioning.
Extending the Input
Now imagine we want to extend the input from n elements to n+p elements. This is often found with natural language processing, e.g. I have a dictionary of n words or characters that are represented as one-hot vectors and I want to add an additional p words or characters. We can represent this as a concatenation of another p length vector – u – onto the end of our original n length vector – x:
x’ = [ xT | uT ]T
and:
y = A’x’
where A’ is a new larger matrix that needs to be m by (n+p).
Now this A’ we can actually consider as a matrix concatenation of our original matrix A and a new m by p matrix B:
A’ = [ A | B]
Here the matrix concatenation is horizontal – a new matrix is added to the right of A. In numpy terms we have a concatenation along the columns or axis 1 (out of axes 0 and 1).
When we perform the matrix multiplication we actually get: y = Ax + Bu (where we are looking at an elementwise addition).
This means we just create a new neural network based on the weights B, feed it the new input u and add the output to the output of our original neural network based on A to create a new output. We can then train end-to-end with the old data (with u set to 0) and new data with triples of (x, u, y).
Extending the Output
We can also do something similar with the output. Say we wish to extend our output from m elements to m + q elements. We can represent this as a concatenation of another q length vector – v – onto the end of our m length vector – y:
y’ = [ yT | vT ]T
and:
y’ = A”x
A” is now a new larger matrix that needs to be (m+q) by n elements.
Now this A” we can actually consider as a matrix concatenation of our original matrix A and a new n by q matrix C. This time we have a vertical or row based concatenation (axis 0).
A’ = [ 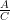
where the original m elements are determined by Ax (y=Ax) and the additional q elements are determined by Cx (v=Cx).
We can thus extend our neural network by adding a new neural network with weights C that takes x as input and outputs v. We can train this using new samples where v is provided (or extracted from y’). The old neural network keeps predicting y as before and can be trained with new samples by only providing the first y terms.
Extending Both
We can also do both at the same time:
y’ = A”’x’
where:
x’ = [ xT | uT ]T , y’ = [ yT | vT ]T and:
A”’ = [ 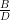
In neural network terms this can be broken down as follows:
- Decompose the input and output into (x, u) and (y, v) as above.
- Keep our original “A” neural network.
- Add a new “B” neural network that takes u as input and outputs a vector of the same length as y. Add the output of this new “B” neural network to the original “A” neural network.
- Add a new “C” neural network that takes x as input and outputs a vector of the same length as v.
- Add a new “D” neural network that takes u as input and outputs a vector of the same length as v. Add the output of this new “D” neural network to the output of the “C” neural network.
- Train the “A” and “B” neural network system using x and u as inputs and comparing with the first m outputs of y‘.
- Train the “C” and “D” neural network system using x and u as inputs and comparing with the last q outputs of y‘.

Biases, Probabilities and Softmax
You probably know that neural networks have biases as well as weights, with the linear matrix equation being y=Ax+b (similar to a regular line but in more than 2 dimensions). In neural networks the bias is typically needed in association with the non-linearity, it enables an output value for an element of y to be shifted up or down in value and thus changes how the non-linearity is applied.
However, as for when we extended the input, we can actually fold the bias into the matrix multiplication by extending A by one row and adding 1 to the end of x. If we want a bias on each of the four feed-forward neural networks A to D above, we can just add a row to the corresponding matrix and add 1 to the end of the input vector x or u.
In many classification neural networks, a softmax layer is used to convert values output by the neural network into probabilities. As this operates as a function over all the output elements (e.g. all of y or y‘), we have to think if we are partitioning the output into y and v.
The softmax function raises each element of the output as an exponential and divides by the sum of exponentials across the elements:
S(y’) =

What it is really doing is converting from a linear sum space to a multiplication space by raising to a power. The bottom term normalises.
If we add another q elements, even if we set the weights of C to zero initially to get v = 0, our sum of exponentials still increases by q (as e^0 = 1), decreasing the likelihoods of our original y probabilities. To not alter our original probabilities we actually need the output of each element of v to be –infinity, as then e^-infinity > 0. This is complicated if we use a RELU non-linearity as all negative values are set to 0, meaning we can’t have large negative values. Also even if we don’t have a RELU, v = Cx and so we can’t just set the weights of C to -infinity (or at least a large negative number) as x maybe -1, in which case our output explodes.
We can maybe keep our original probabilities if x has a bias term (i.e. a last value that is 1). In this case we can initialise matrix C to have all zeros with a last column of large negative values (e.g. representative of -infinity within finite precision). This way we can predict large negative outputs. But we need a non-linearity that allows saturation at negative values.
We would also need similar initialisations for D.
