When you work for a long time with artificial neural networks, you begin to see patterns emerge. One of these touches on fundamental aspects of intelligence. As I haven’t seen it described very often, I’ll set it out here.
Encoder-Decoder
Many neural network architectures operate based on an encoder and decoder model. Data is shovelled in at the input, is encoded into an intermediate or “compressed representation”, and then is decoded to generate output data. This output data may be a reconstruction of the input or some new form.

Machine translation is one of the earliest examples. The input data is generated based on a sentence in a first language and the output data is a translated sentence in a second language. Video and audio encoding work in a similar way, but there the idea is for the output data to be as close to the input data as possible. You can also have complex variations on this theme where you have, say, text input and an image output or vice versa.
Encoding as Encapsulation
In the older field of signal processing, encoding has often been seen as a form of encapsulation. This maybe comes from the early days of letter writing where you “encoded” data in the form of a letter by placing it in an envelope, sealing it, and sending it to your destination.

Indeed, if you are talking about computer networks encoding often involves encapsulating data within packets. “Coding” or “encoding” here is seen as adding layers of information to protect your original data from noisy communication channels or interception.
In more advanced video and audio coding, a similar framework is used, but here an aim is to throwaway bits of the original data that may not be used or noticed by human beings. In this case, the output data is meant to be the original data, but may be a little dog-eared and soggy (think about those blocky pixels or muted ranges).

This understanding assumes that you can retrieve your original input data or at least a version of it, that there is a true, original form of your input data. Even in neural network autoencoders this aim is often still under the surface, your aim is to recreate the original input data as well as possible.
Encoding as Toothpaste
On the image processing side of neural networks, the convolutional neural network (CNN to its friends) reigns supreme. Often you are presented with an encoder-decoder architecture similar to the sketch above, where an original image is “squeezed” into a bottleneck encoding and then “unsqueezed” into whatever form you want your output to be (e.g., an image mask).
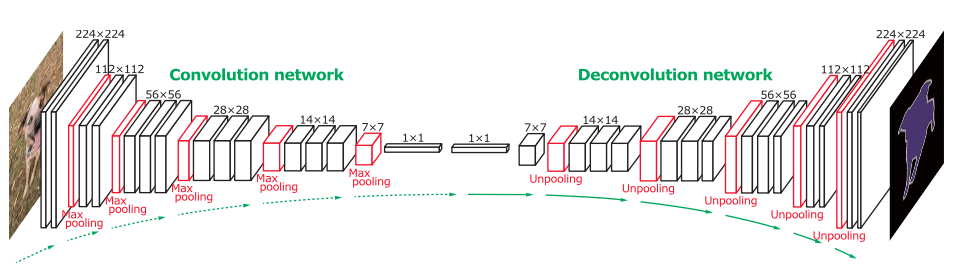
The normal way of thinking about this form of architecture is that the central, long narrow representation is somehow a condensed version of the original image, its essence or whatnot. I often feel it is implicitly assumed that the central “encoded” representation is the image in some manner, despite a loss of information. This has analogies with video and audio encoding where a poor or small encoding is still the audio or video, just a poor quality version.
People tend to make a similar assumption with DNA. They believe that DNA is an encoding of a person, that somehow a person’s “true” essence is compressed into this little code that allows the person to be reconstructed.
Ignoring the Process
I have found many of these existing explanations wanting. They seem to be missing something.
Now, there is another way to think about encoding. This way reflects much more accurately how messy natural phenomena like brains and language actually work. It also better explains what neural networks are doing and why they often work.
The key is to consider encoding and decoding flipsides of the same process, where the process is baked in. Let me explain.
Rather than encapsulating or condensing information, good encoding embodies assumptions about the environment that is producing the data. You are somewhat counterintuitively representing variation with reference to regularities. If the encoder and decoder, within their structure, represent the regularities, then all you need to do is indicate how these regularities are combined to produce some data.
Generative Functions
This is where generative functions come in.
Generative functions are mainly discussed in fields that deal with probabilities. Traditionally, generative functions referred to algorithms that were configured to generate data samples that were representative of an original data distribution.
Take a coin toss. You know that the outputs are “heads” or “tails” with a 50% chance of each (with an unweighted coin). A simple generative algorithm receives a random number between 0 and 1, if it is >= 0 and < 0.5 it outputs “heads”, if it is >=0.5 and < 1 it outputs “tails”. Run this for 100 iterations and you’ll get a list of “heads” and “tails” that you’d be hard-pressed to distinguish from a version of the same list obtained from manual counting.

Many generative functions as defined as a function on a set of random numbers, R, to produce a representation of data, D’:
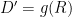
Normally, the generative function is a general function that is tailored to specific cases by a set of parameters, 
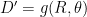
Or in English, your output representation of the data D’ is a function of some random input (a random number or list of random numbers) and a set of defined parameters
Generator = Decoder
Now, you’ll see that a generative function as defined above is actually the same as a function definition for a neural decoder:
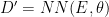
where NN is the neural network, E is the encoding and
In this case, our set of random numbers, R, and our encoding, E, seem to have the same function. This appears strange, because surely random numbers contain no information but an encoding is meant to store all the information?
The difference comes from the two traditional uses of the generative function and the decoder: the former is arranged to produce random data samples and the latter is arranged to produce specific data samples. You can use a generative function to produce a specific data sample if you provide it with specific not random data. We have the challenge of picking the right set of random numbers to produce a desired specific output data sample.
With generative neural network models, modellers often play around with different inputs (R or E) to work out what they do and how they change the output. They can then pick particular values to try to influence the output.
Reversibility & Irreversibility
Now, neural network architectures are typically irreversible. They take an input I and map it to an output O, I>O, but cannot take the same output and map it to the input O>I.
This is fine for image or text classification, where you are going from a very high number of data values to a much smaller number of data values. Images have millions of pixels, where each pixel has three different colour values; classification classes are normally in the 10s or 100s (there are only ~105 noun lemmas in English). What these classification neural networks cannot do is generate an example of an image from an input classification (say produce an image of a bird from the category “bird”).
It’s worth while thinking a little about why you have this tendency to irreversibility.
We can imagine many, many different examples of images that might be labelled as “bird”. Asked to draw a “bird” there is no single right answer. In fact, if you allowed imaginary birds there would seem to be an infinite or at least very large set of possible “right” outputs for an input of “bird”. This is especially true if we think at the level of pixel values – just changing an 8-bit pixel value by 1 is typically unnoticeable but technically results in a new combination of pixel values.
In our representation of “bird” there is simply not enough information to reconstruct image values from the encoding “bird” itself.
In image classification, we are producing a form of one-way hash function – we cannot reclaim the image from the classification like we cannot reclaim a hash-input from the hash-output.
Brains
So how do we do it?
A first thing to consider is that it is the label “bird” that is unusual in this situation. The real world is experienced and measured through messy high-dimensionality input – the input image. Language is a relatively late development in the natural world and only humans seem to have it.
Starting from the high-dimensionality input, it doesn’t make sense to act on the individual elements of the input. Individual data samples such as pixel values, time samples, and chemical measurements have too many different configurations and there are too many of them. The result is confusion and chaos.
What does make sense though is to pick out the regularities in our environment, and do this via the regularities in our sensory input. If a combination of input signals occur together some of the time, it makes sense to represent the regularity rather than the values of the original set of input signals. The representation of the combination also has the benefit that you can have flexible criteria on the combination, e.g. if one of the input signals doesn’t always occur by the others the representation may be probabilistically mapped to the input signals. As long as the representation is re-used over time, and the activation of the representation allows better action as compared to chance, it does not need to be perfect.
Now where is this representation stored?
The “encoding” of the representation can be a single value indicating whether the representation (i.e., the input pattern) is present or not. But most of the important information is stored not in the encoding itself but in the structure that outputs the encoding. For example, if we have:

where E is the encoding and D is the input data, the information is actually primarily stored in
Now there is always a tension between storing information in E and storing information in
