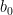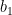This post continues my explorations of simple intelligence.
In this post, we’ll consider some elementary sensing cells. We’ll then look at whether we can apply local function approximators.
Sensors
Consider a set of sensing cells, which we’ll call “sensors”.
We have N sensors, where each sensor measures a value over time. This value could be a magnitude or intensity, such as a lightness or colour intensity for vision, a frequency magnitude for sound, or a level of cell damage for pain. We’ll assume the N sensors form a small group – possibly a receptive field. The N sensors could therefore form part of a cortical column.
We can represent the set of N sensors as a column vector. The column vector represents a measurement at one point in time. We’ll represent each sensor using an index 


Note: we’ll start counting things in this post from 0 (as this matches Python implementations). This means that if we have N sensors our vector ends with the N-1th entry.
Measured Functions
To start, we can imagine that the measurements of each sensor conform to a function.
The function may be considered a function of time that is specific to the sensor. This gives us:

To makes things easier, we’ll consider a quantised or discrete time base. Hence, t has integer values from 0 to 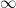
If we collect batches of samples (i.e. measurements) from the sensors over time, we can pop these into a matrix form 


(Note: I use P instead of T to avoid confusion with the transpose operator – T – which we’ll use later.)
Covariance
We can use 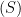
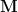
Now officially we shouldn’t do this. Our samples are not I.I.D. – independent and identically distributed. Indeed, our function assumes there is some dependence over time. It is also likely that probability distributions for the sensor intensity change with time. But let’s play around for just one post to see what happens when we mix the streams. In effect, we are considering each time step to be an independent trial with a common intensity probability distribution, yet also considering each sensor to record a function over time.
Mean Adjustments
When dealing with a number of statistical samples, it is recommend to start by adjusting the data to have a mean of zero. This means that we need to subtract the mean measurement of each sensor over the time period from the sensor readings for that sensor. Let’s call the mean for the time period 
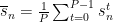
We need to be a little careful. Because we are using an discrete integer time base where a time index is incremented by 1 at each time step, we can substitute P for the number of samples. If we were using a different time base, this would not be possible.
To get a mean adjusted set of measurements, we perform a column-wise subtraction:

This gives us an adjusted data sample matrix 
Covariance Calculation
Given the adjusted data sample matrix
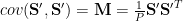
(Note: sometimes this is written as simply 
In the above calculation, we have a first matrix 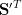
Now we’ll just park our covariance matrix for a moment. We’ll need it later when we look at decorrelating the sensor readings. But now we’ll go on a little detour into function approximators…
Taylor Polynomials
Let’s return to our sensor measurements over time.

From before, we considered that we can model each sensor with a function that changes over time: 
Consider a moment. This one. That one. Any moment.

We can approximate the sensor function 


If we consider a moment at t=0 then this becomes a Maclaurin series:

Now, we can use this to determine an approximation to the function at the moment. As the series is a sum of terms we can take different groups of successive terms as different levels of estimation. The first term is a relatively poor estimate, the first and second terms are better but still reasonably poor, the first to third terms are better again but still not as good as having more terms etc. You may have come across a similar approach when considering the mathematical notion of moments (although these are unrelated to our “moment” in time). The underlying idea crops up a fair amount across different fields, annoyingly referred to as different things in each field.
The moment in time matters because the accuracy of approximations is centred around the moment. The further away from the moment, the greater the divergence from the actual function. You can see this in the following example of approximating 
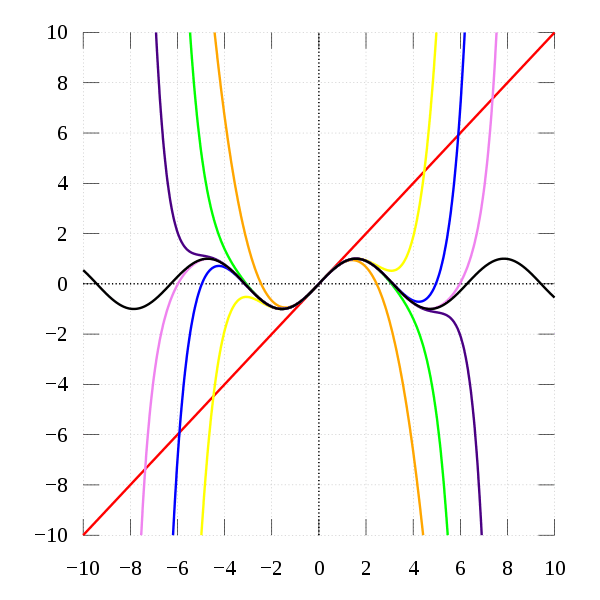
The approximation becomes increasingly bad the further we stray from 0.
Now if we consider the Maclaurin series of the function 


We can also consider the set of sensor signals as separate functions that are approximated with different coefficients:
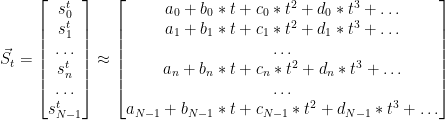
We can then rewrite this in tensor form.
(Aside: these expressions may remind you of the equations of motion – indeed for motion these form of approximations work well with low powers such as 1 or 2. It’s interesting to consider that motion and orientation within space are some of the earliest tasks that require intelligence.)
Now time series data provides for some interesting tricks. A first is that all our sensors are operating according to a common time base. Hence, we have a set of vector * scalar multiplications:
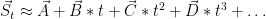
Where:



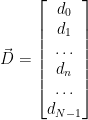
Now we can consider the form of our mean adjusted vector 
First, let’s determine our mean vector using the Taylor polynomial:



This assumes we are evaluating the mean using the function approximation about 0.
What we are left with for the mean signal 
Now if we look at a mean adjusted signal using our new expression for the mean:


Now this reminds me a little of our original Taylor series expansion, only performed around the mean time period.
Rebasing
The expression above gives us a clue that we might reformulate our series sums around different moments within our time period.
If we have an incremental integer time base, from 0 to P-1, there are P integer values, where the mean value is:

(Note: We can use Faulhaber’s formula for the sum.)
But if we shift the P time points to be centred on t=0, we get 
To play nice with an integer time base, we’ll look at P points that include 0. For example, we can run from -(P-1)/2 to (P-1)/2 (the “-1” enters in because we have “0” as an number as well).

This also has the nice characteristic that, in the average over time for our sensors, odd terms will cancel out either side of 0.
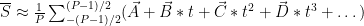

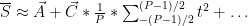

As you can see, the odd terms have a time average of 0 and so disappear in the expression.
Now the above average has been evaluated about t=0. We need to do this for our sensor function approximations as well. We can then look at the mean adjusted values:
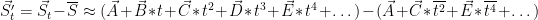

Back to Covariance
Still with me?
Now we have an expression for a mean-adjusted sensor reading, we can look at expressions for the entries in the covariance matrix. Each entry is equivalent to taking a row from
The row-column multiplication for each entry is equivalent to multiplying each mean-adjusted time entry for the ith sensor by a corresponding mean-adjusted time entry for the jth sensor, and then summing the result across the P readings:

We can then use our determination for the mean-adjusted signal to get an expression with our Taylor series terms:
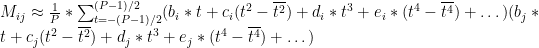
What’s interesting here is we find re-occurrence of odd powers of t. When terms with these odd powers of t are evaluated over the sum of time steps, they go to zero, e.g.:
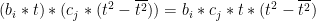
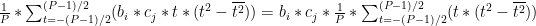
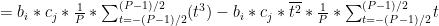
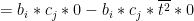
Simplifying Terms
To help simplify things we can use Faulhaber’s formula to determine some of our 
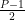




Power Iteration with the Covariance Matrix
One way to compute the eigenvectors of the covariance matrix is to use the power iteration method. This involves multiplying a random vector by the covariance matrix multiple times. As we iterate this multiplication (and often scale the result), we move towards a vector that resembles the first eigenvector. We then deflate (i.e. remove the contribution of the first eigenvector) and repeat to determine the next eigenvector.
If our covariance matrix is 
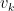
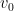

And scale it is recommended to scale the new vector 

Linear Approximations
Now, to avoid getting lost in higher terms, and to try to work out what neural networks are doing, we can consider just the linear terms in our Taylor polynomial.
Let’s start by ignoring any terms above 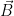
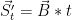
The leftovers or error of this approximation is:

Notice how, following the mean adjustment, we don’t need to worry about a bias term.
Our covariance matrix terms for the linear approximation become:
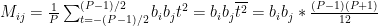
Power Approximations
What happens to our linear approximation when we try to compute the first eigenvector using the power iteration method?
Let’s consider a small test case with 2 sensors and 7 readings (N=2 and P=7).

If we start with a vector 
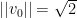

Our scale factor becomes 
On each iteration, we get different combinations of power terms occurring, and a longer and longer scale factor. In simple 2×2 matrix examples I’ve seen it takes about 10 iterations to converge.
As the covariance matrix is symmetric, with a 2×2 example we only have differing terms on the diagonal. As we iterate using the power method, we have a number of terms that are shared by both vector elements and a number of terms that are not shared. The terms that are not shared influence how the vector changes over time, and these non-shared terms are increasingly influenced by the differing diagonal elements, while the scaling at each iteration stops explosion to infinity.
We can also see that P does not affect how the unit vector changes, it just sets an external scale factor. Also our time period does not really matter; what matters is the sampling rate over our time period. P only really matters for the accuracy of the approximation, which can be seen in the illustration above. A large value of P means that outer approximations (e.g. values of
Even with the simple 2×2 example above, we also see that there is no inherent pattern for the first eigenvalue – it’s direction depends on the relative values of